Hadoop之HDFS
1. 简介
HDFS的全称是Hadoop Distributed File System,即Hadoop分布式文件系统。HDFS与一般的分布式文件系统(如KASS、DFS等)最大的区别是HDFS的高度容错性,它可以部署在廉价的机器上而不用担心文件的丢失。此外HDFS能对外提供高吞吐量的数据访问。
2. 基本概念
2.1. 数据块(Block)
在HDFS中最基本的存储单位是64M的数据块,但如果一个文件小于数据块的大小,并不会占用整个数据块存储空间。通常一个数据块会保存三份,并存储于不同的数据节点中。
2.2. 数据节点(Datanode)
集群中的数据节点一般是一个节点一个,管理它所在节点上的存储,主要负责处理文件系统客户端的读写请求。在元数据节点的统一调度下进行数据块的创建、删除和复制。
2.3. 元数据节点(Namenode)
元数据节点是一个中心节点,它负责管理文件的名字系统以及客户端对文件的访问。它要负责确定数据块到具体数据节点的映射,以及文件系统的名字空间操作,如打开、关闭、重命名文件或目录。
2.4. 从元数据节点(Secondary Namenode)
从元数据节点不是元数据节点的备用节点,它主要的功能是周期性地将元数据节点的命名空间镜像文件和修改日志合并,防止日志文件过大而引起的元数据节点启动太慢。
2.5. 修改日志(EditLog)
修改日志用来记录任何对文件系统元数据产生的修改,存储在元数据节点所在本地操作系统的文件系统中。
2.6. 命名空间映像文件(FsImage)
命名空间映像文件包含了整个文件系统的名字空间,包括数据块到文件的映射、文件的属性等,它也存放在元数据节点所在的本地文件系统上。
3. HDFS架构
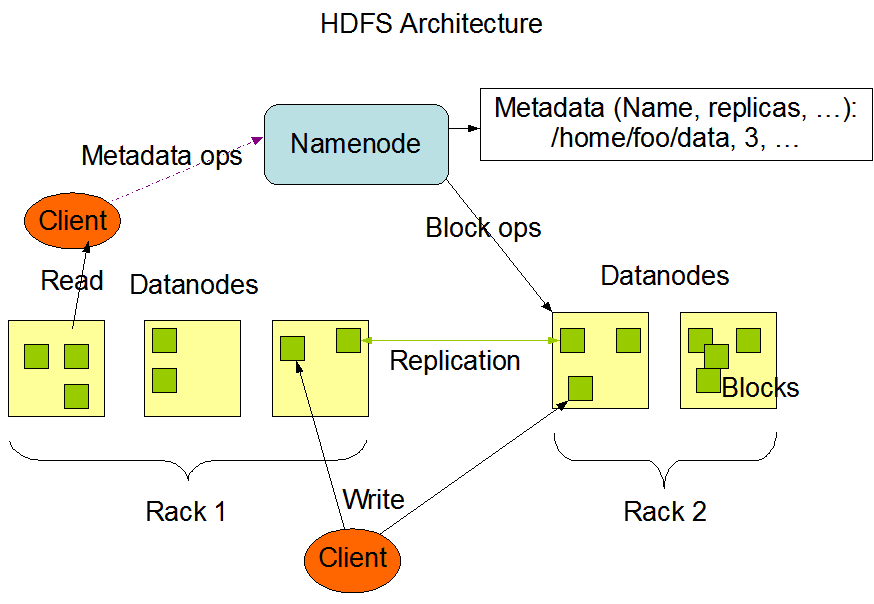
4. 文件读写
4.1. 读文件
- 客户端向NameNode发起读文件的请求
- NameNode返回文件所在的DataNode的信息
- 客户端读取文件信息
4.2. 写文件
- 客户端向NameNode发起写文件的请求
- NameNode根据当前情况返回相应DataNode的信息
- 客户端将文件划分成多个Block,按序写入DataNode中
4.3. 写文件的额外考虑
当新增数据块时,NameNode在选择DataNode接收这个数据块之前,会考虑到很多因素。其中的一些考虑的是:
- 将数据块的一个副本放在正在写这个数据块的节点上。
- 尽量将数据块的不同副本分布在不同的机架上,这样集群可在完全失去某一机架的情况下还 能存活。
- 一个副本通常被放置在和写文件的节点同一机架的某个节点上,这样可以减少跨越机架的网络I/O。
- 尽量均匀地将HDFS数据分布在集群的DataNode中。
5. HDFS的优缺点
5.1. HDFS的优点
- 处理超大文件
- 流式的数据访问
- 运行于廉价的商用机器集群
5.2. HDFS的缺点
- 不适合低延迟数据访问
- 无法高效存储大量小文件
- 不支持多用户写入及任意修改文件